
导语:在众多被赋能的行业中,AI+投研,成为了一个炙手可热的赛道。
准确预测未来,并在关键时刻扼住命运的咽喉,做出正确的决定。
这是无数人梦寐以求的情景。
得益于算法的进步,这样的现实,正离人类正越来越近。
2012年,美国康涅狄格大学生态学和数学教授彼得·图尔钦(Peter Turchin)在《和平研究杂志》上发表了一篇研究论文,提出一个不祥的预测:美国将在2020年迎来社会动荡的“高峰”。

结果,美国真在2020年迎来了“大乱”。
疫情、种族冲突、金融危机,将整个社会搅成了一锅粥。
那这位叫图尔钦的教授,为何预测得这么准?
原因就在于,他本人是一个“数据史学”的忠诚信徒。
所谓“数据史学”,简单来说,就是搜集历史上的各种关键数据,如人口、收入水平、暴力事件的频次等等,之后通过大数据+机器学习的方式,对其进行建模、分析,从中预测出未来的趋势。
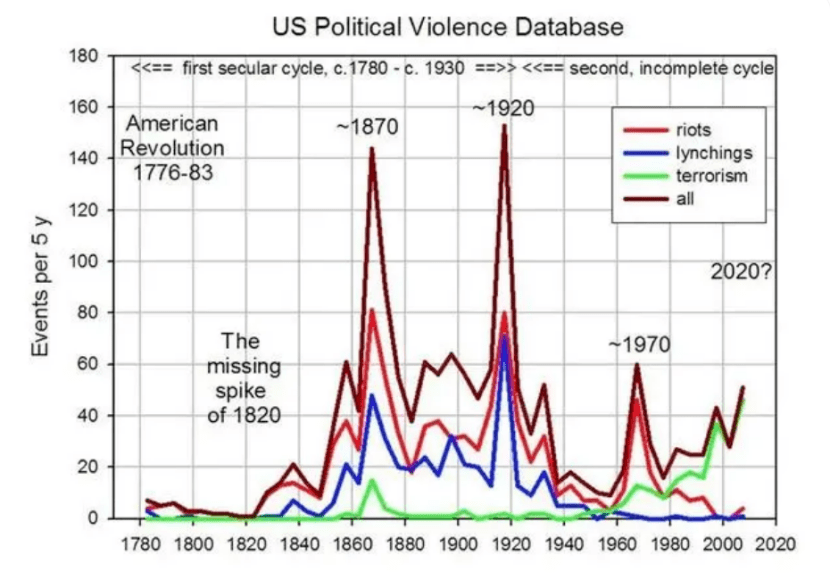
用这样的分析方式,图尔钦甚至算出,平均50年,美国就会经历一次“动乱周期”。
除了用来分析“天下兴亡”之外,这样的技术思路,也扩展了一个需求庞大的赛道——机器(AI)数据分析。
根据MarketsandMarkets的报告,全球机器数据分析市场规模在2020年达到了14.8亿美元,预计到2025年将增长至45.4亿美元,期间年复合增长率(CAGR)为28.3%。

而在众多被赋能的行业中,AI+投研,成为了一个炙手可热的赛道。
01 数据炼金术
2023年至今,全市场一共开了52,400场投研会议,差不多每天200场。在信息爆炸的年代,信息降噪、提纯成为投研人士的新刚需。
为此,在互联网时代的早期,就有不少投研机构、平台开始用数据模型的方式,来分析庞杂的金融数据。
其中,最著名的就是彭博社推出的Bloomberg Terminal(彭博终端),这是一个为金融专业人士提供实时金融数据、新闻和分析的平台。
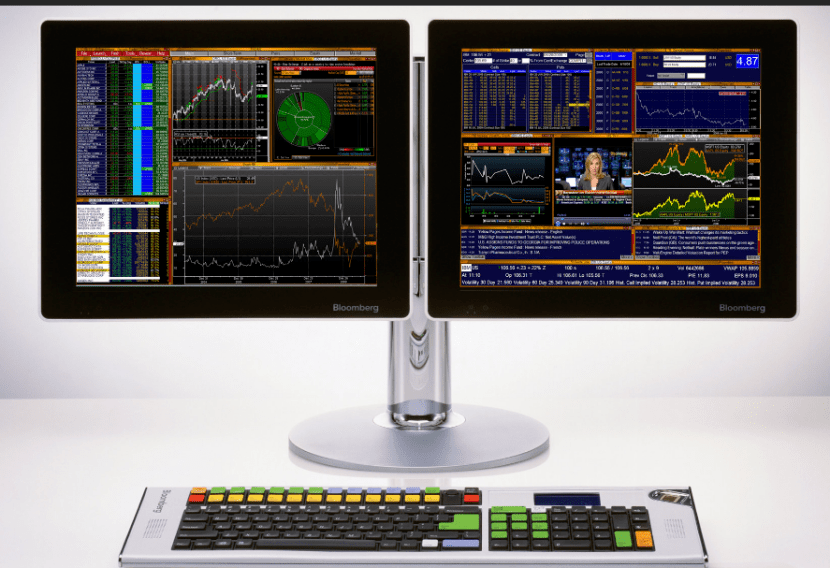
通过预构建的金融模型和指标,例如财务比率、估值模型、风险分析模型,以及各种图表和可视化工具,Bloomberg Terminal可以分析来自300多个交易所和500多个数据提供商的数据,从而帮助投资者实时了解市场动态,制定投资策略。
除此之外,S&P Capital IQ也是基于类似的技术思路研发的分析工具。
在提供了各种预制的财务模型模板,例如贴现现金流(DCF)模型、比较公司分析模型之外,用户还可以利用插件直接在Excel中调用S&P Capital IQ的数据,利用Excel的公式和功能进行深入的财务分析。

从功能和分析方式上来说,这些平台大多都是以预设的模型、算法,结合财务报表、历史交易数据等结构化数据,对金融市场的走向进行分析。
尽管这些终端都在努力整合、处理大量金融数据,但在技术层面上,其仍存在着各种局限,而其中最大的局限之一,就是对非结构化数据(如新闻、研究报告等)相对薄弱的处理能力。

对于金融数据来说,结构性的数据(如财务报表、交易记录等),只是浮在海面上的一小层冰山。而更多的非结构性文本(新闻、社交网络信息),才是隐藏在海面之下的,价值更大的冰山。
这是因为,随着互联网的不断普及,大量的文本信息被生成并存储在网络空间中。

根据皮尤研究中心(Pew Research Center)的一项研究,从2008年到2018年,全球金融新闻报道的数量增长了约40%。这些报道涵盖了股票、债券、外汇等各种市场动态。
然而,想要挖掘这些文本数据组成的“金山”,就需要运用如自然语言处理、大数据分析等先进的技术,才能从非结构性的文本中,提取有价值的信息。

为此,不少以自然语言处理技术(NLP)为核心的投研AI纷纷涌现,由此开启了金融数据分析的一个新阶段。
02 化简为繁
当下的大模型+金融赛道,入局者甚多。
然而,在NLP技术没有绝对性差距的情况下,要想在以自然语言处理技术为核心的投研AI中脱颖而出,高质量、多样化且实时更新的金融数据源,就成了竞争中的关键。
因为数据的质量和多样性,将直接影响到分析结果的准确性和可靠性。
而在这方面,熵简科技,试图站到行业的前列。

“熵”是热力学中描述系统混乱、无序的程度。
“熵简” 寓意以技术手段简化业务数据的复杂度,用“化繁为简”的方式,帮助用户在数据中获得洞察。
而其研发的新一代智能引擎AlphaEngine,就是这种理念的最佳体现。
AlphaEngine不仅聚合了海量优质商业情报数据源,内涵三大商业数据库,并且深度融合AI能力,能够帮助用户在海量数据中快速获取洞察。

具体来说,AlphaEngine内涵的三大商业数据库,分别是会议纪要数据库、研究报告数据库、行业经济数据库。
其中的会议纪要数据库,不仅会提供全面的会议纪要数据库,包括主流券商电话会议、调研会议纪要、专家访谈纪要等一手研究资料。
而研究报告数据库,则了涵盖主流券商研报、产业咨询报告、外资券商研究报告等专业投研资料。具有多种筛选器,方便用户定位所需资料。
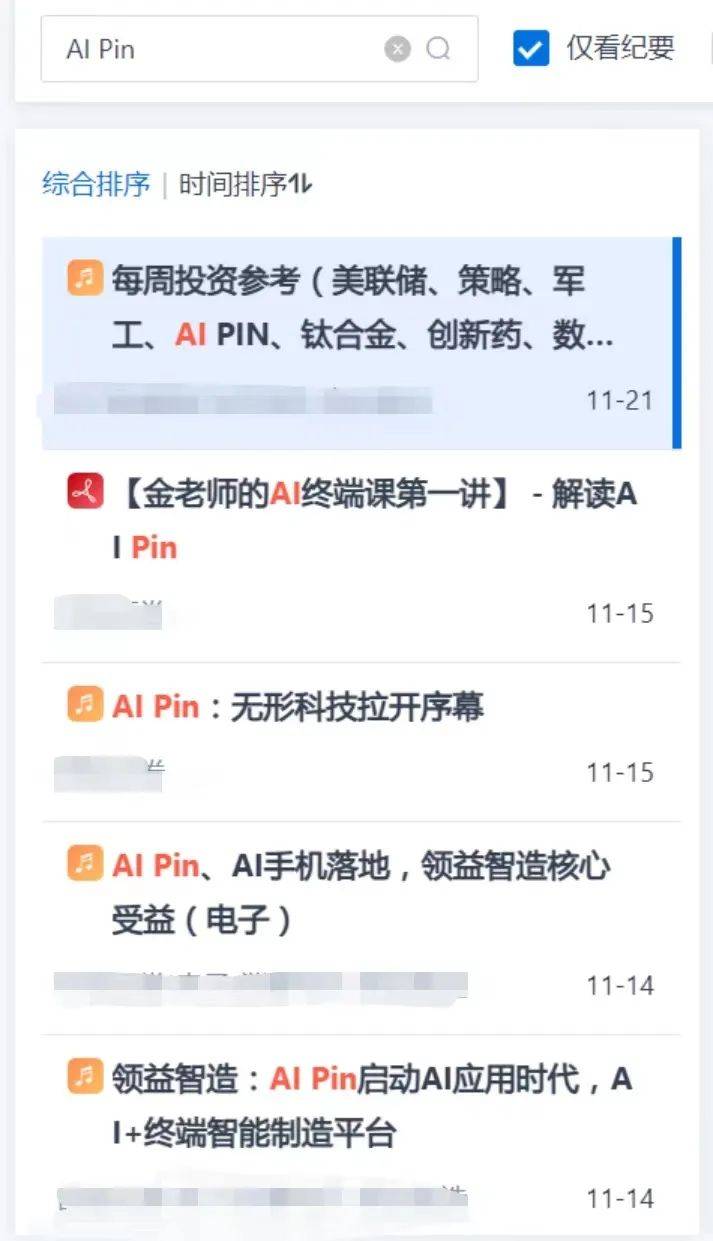
同时,为了使用户在大量数据中,高效找到需要的信息,AlphaEngine提供了多种筛选器,通过使用高效的信息检索技术和数据挖掘方法,使用户能够轻松地在大量数据中找到所需资料。
在AlphaEngine中,以NLP技术为核心的生成式AI,被用于文本预处理、查询处理、语义理解等环节。通过使用NLP技术,AlphaEngine能够更好地理解用户查询和文档内容,从而提高信息检索的准确性和效率。
而在文本摘要、总结方面,熵简科技通过FinGPT大模型,实现了自动化生成AI摘要,从而让用户能方便、快速地获取会议中的关键信息。
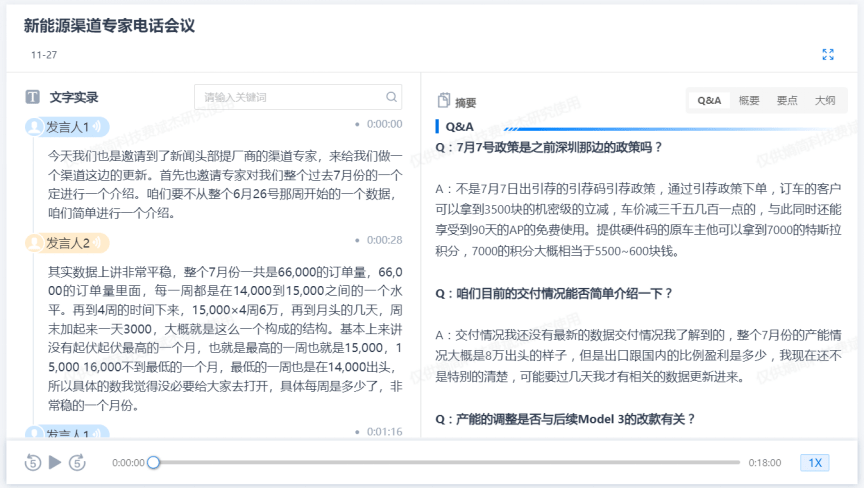
在浏览行业报告时,AlphaEngine内嵌的生成式AI,会自动将报告中的要点、关键信息进行总结、提炼,在节约了用户视角的同时,从而让用户在整体上对报告的核心内容有了清晰的认知。
除此之外,针对一些较为重要的会议、演讲,AlphaEngine也能将会议录音转录成文本,并且形成会议摘要,并支持定位播放及摘要溯源功能,方便用户快速获取会议关键信息。

AlphaEngine除了提供三方海量会议纪要外,也可以用于构建属于自己的AI知识库。
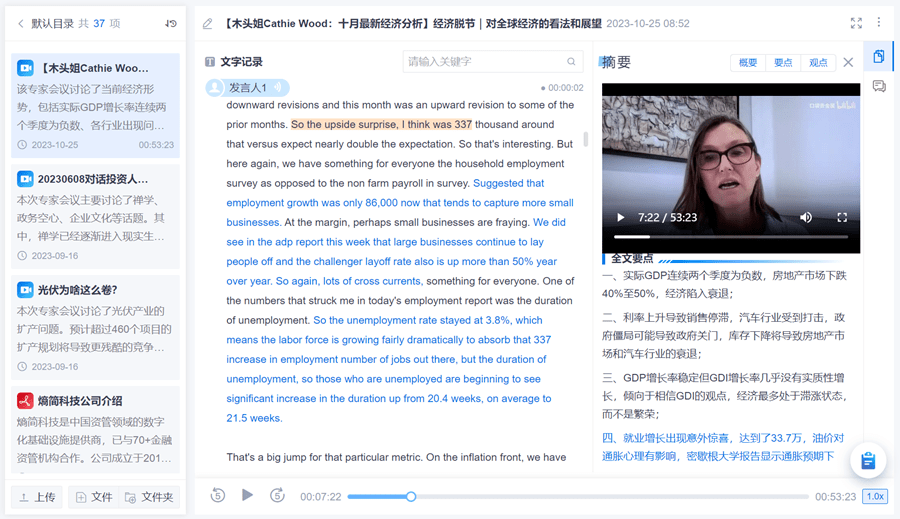
在【知识库】模块中,可以整理任何类型的研究资料,大模型会自动进行音频转写及全文摘要,包括但不限于PDF、Office文档、音频、视频等格式的文件。
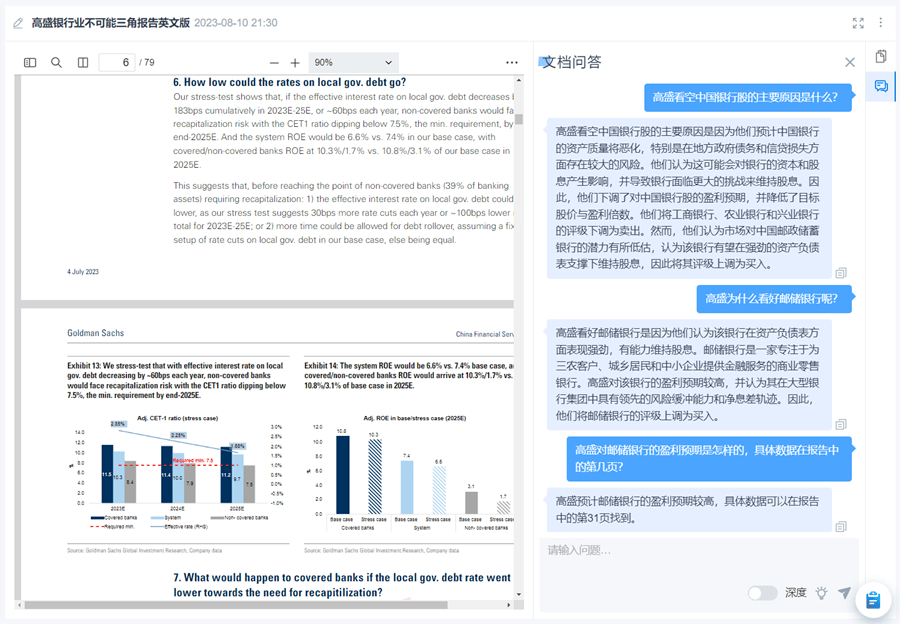
也可以对任意资料进行提问,让大模型根据资料中的信息做出专业解答。
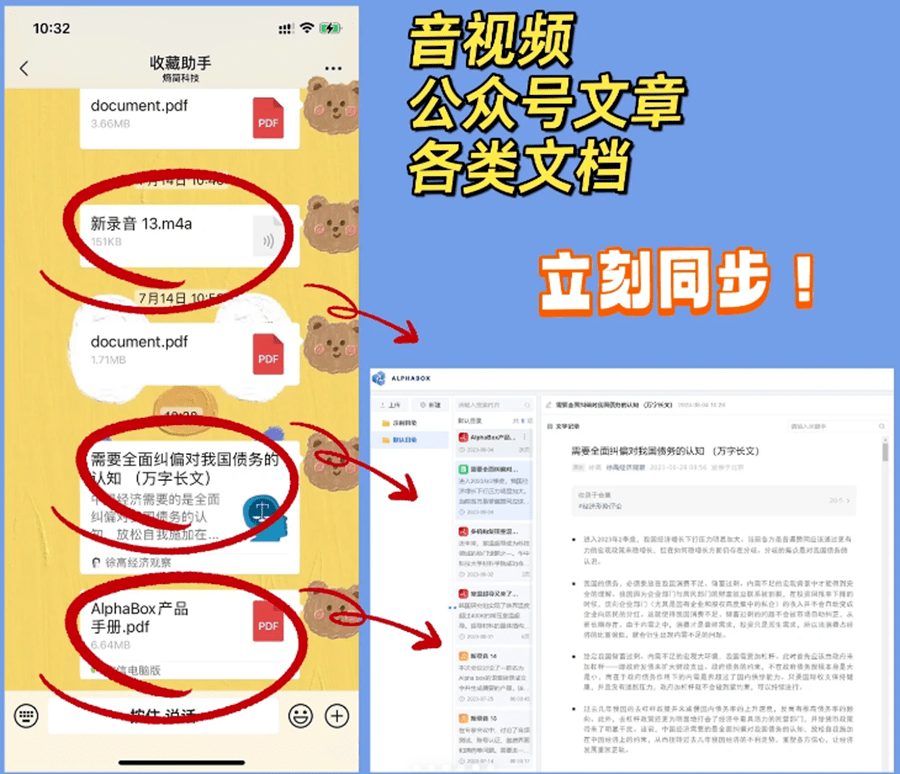
对于手机上发现的优质研究资料,只需把这篇文章转发到微信助手,AlphaEngine会将文章自动同步至知识库中存档,可以在【个人中心】-【微信助手】中进行设置。
上述的技术特点,展现了熵简在处理非结构性金融数据时的巨大优势。
随着生成式AI的重大进展和衍生应用带来的领域拓宽,可以想见,未来熵简也将在AI+数据分析的赛道上,研发出更多有价值的技术或产品。
而这种基于AI的数据分析技术,也是当下处于飞速变化中的社会所期待和需要的。
毕竟,在划时代的机遇来临时,唯有敏锐地捕捉变化,洞察先机,才能找到在新时代的生存发展之道。
而现在,这样洞察先机的机会,就摆在眼前。

