

蓝鲸新闻4月30日讯(记者 武静静)赶在了五一节前,阿里巴巴开源新一代通义千问模型 Qwen3。据介绍,其参数量仅为 DeepSeek-R1 的 1/3,成本大幅下降,但性能表现不错。
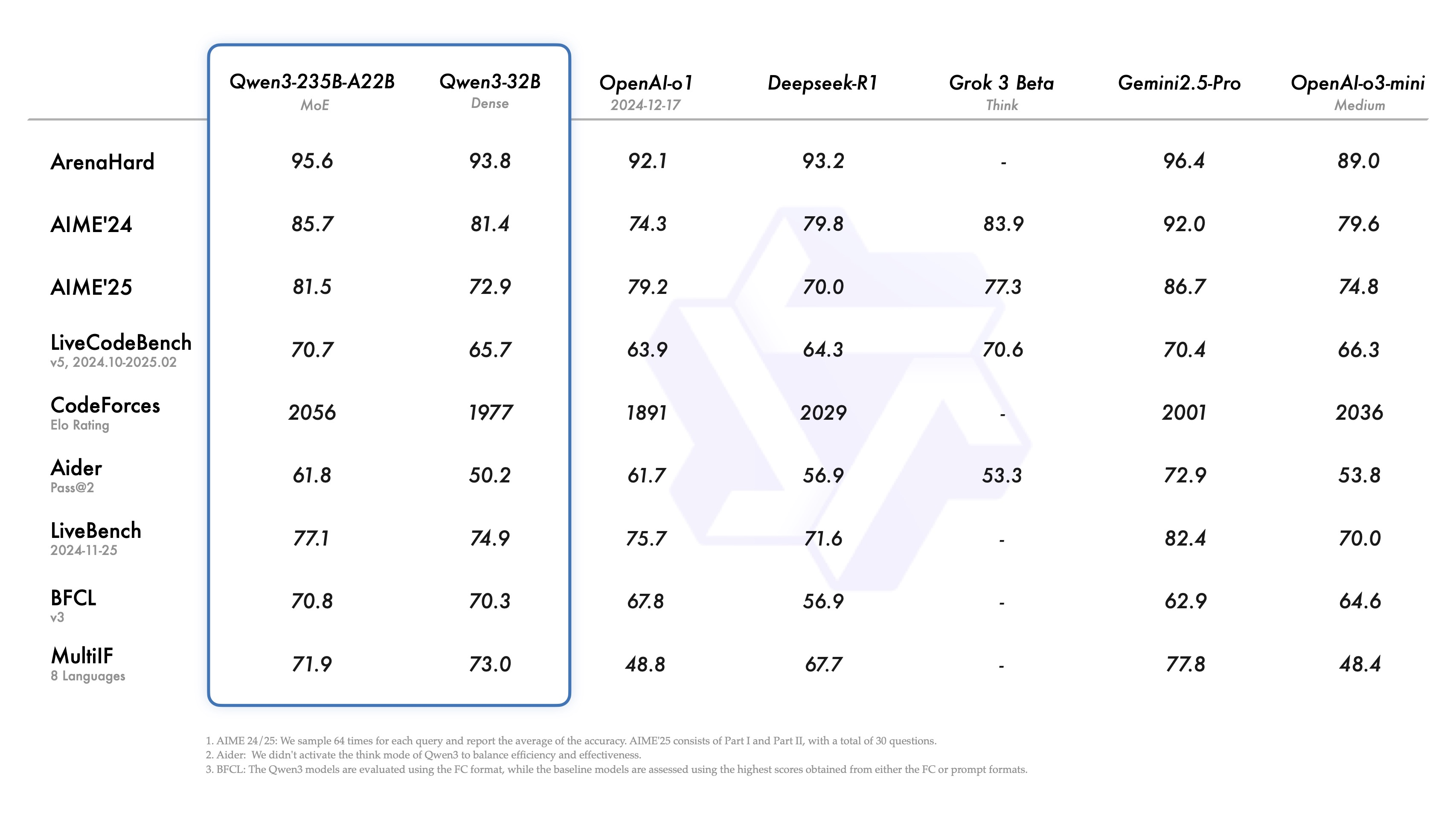
报告显示,Qwen3-235B-A22B 在代码、数学、通用能力等基准测试中,超过了与DeepSeek-R1、o1、o3-mini、Grok-3 和 Gemini-2.5-Pro 等全球顶尖模型。成为了全球最强的开源模型。
通过模型架构的改进、训练数据的增加以及更有效的训练方法,Qwen3实现了模型体积更小情况下,性能表现也比更大参数规模的Qwen2.5基础模型要好。特别是在 STEM、编码和推理等领域,Qwen3 Dense 基础模型的表现甚至超过了更大规模的 Qwen2.5 模型。
博客中,阿里称,Qwen3 Dense 基础模型的整体性能与参数更多的Qwen2.5基础模型相当。例如,Qwen3-1.7B/4B/8B/14B/32B-Base 分别与 Qwen2.5-3B/7B/14B/32B/72B-Base 表现相当。
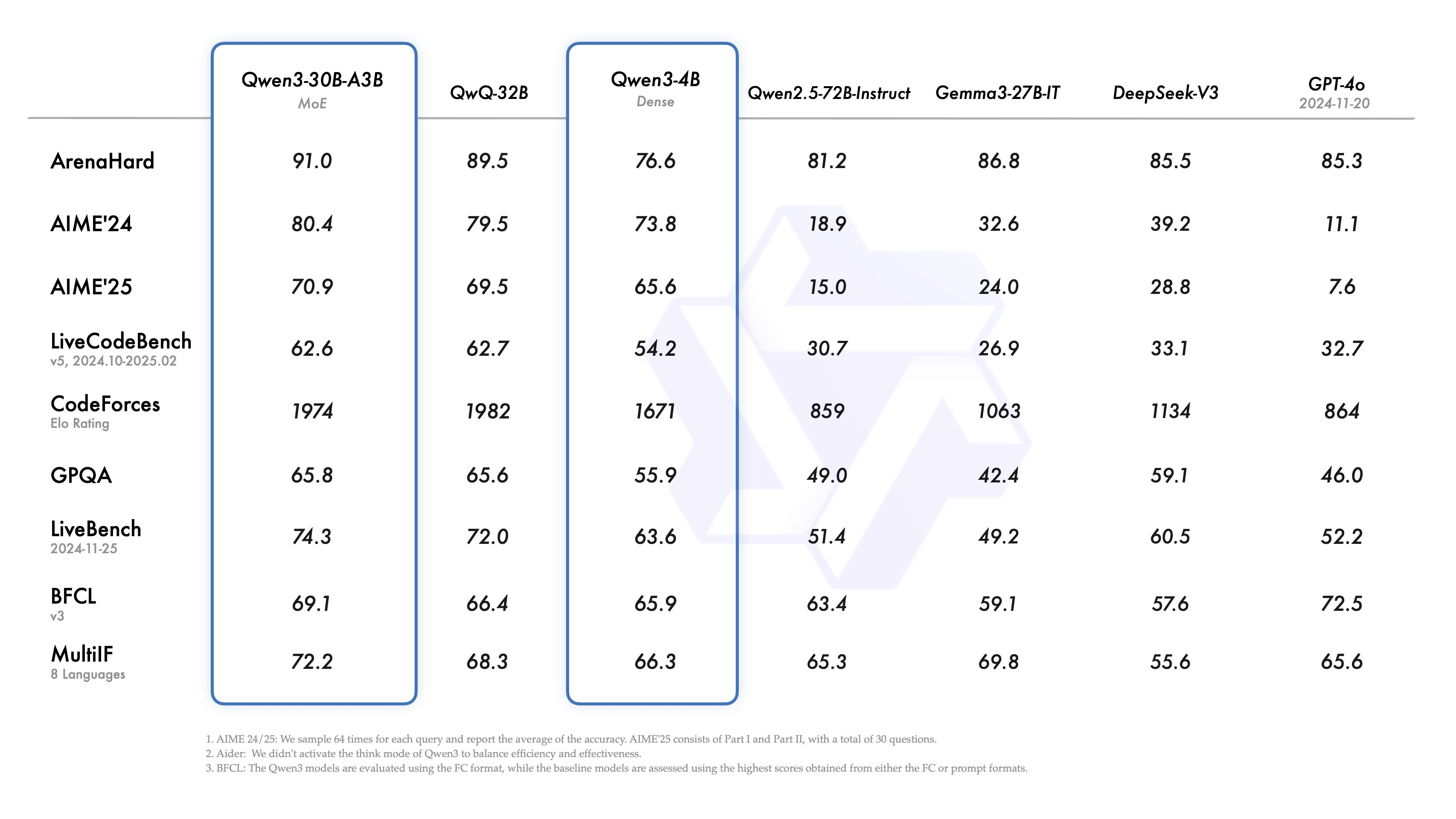
有意思的是,除了拥有235B参数的MoE模型外,Qwen 3还配备了一个小型MoE模型,即Qwen3-30B-A3B。该模型的激活参数量为3B,不及QwQ-32B模型的10%,然而其性能却更为出色。
我们可以把MoE架构理解为一个大型的客服中心,其中有许多专门处理不同问题的专家——有的专家专门处理技术问题,有的专家处理账单查询,还有的专家负责解答产品使用问题。在大模型训练过程中,当数据进入模型中后,大模型会像“客服中心”一样,根据问题的性质被分配给最合适的专家来解决,可以提高查询的计算效率。
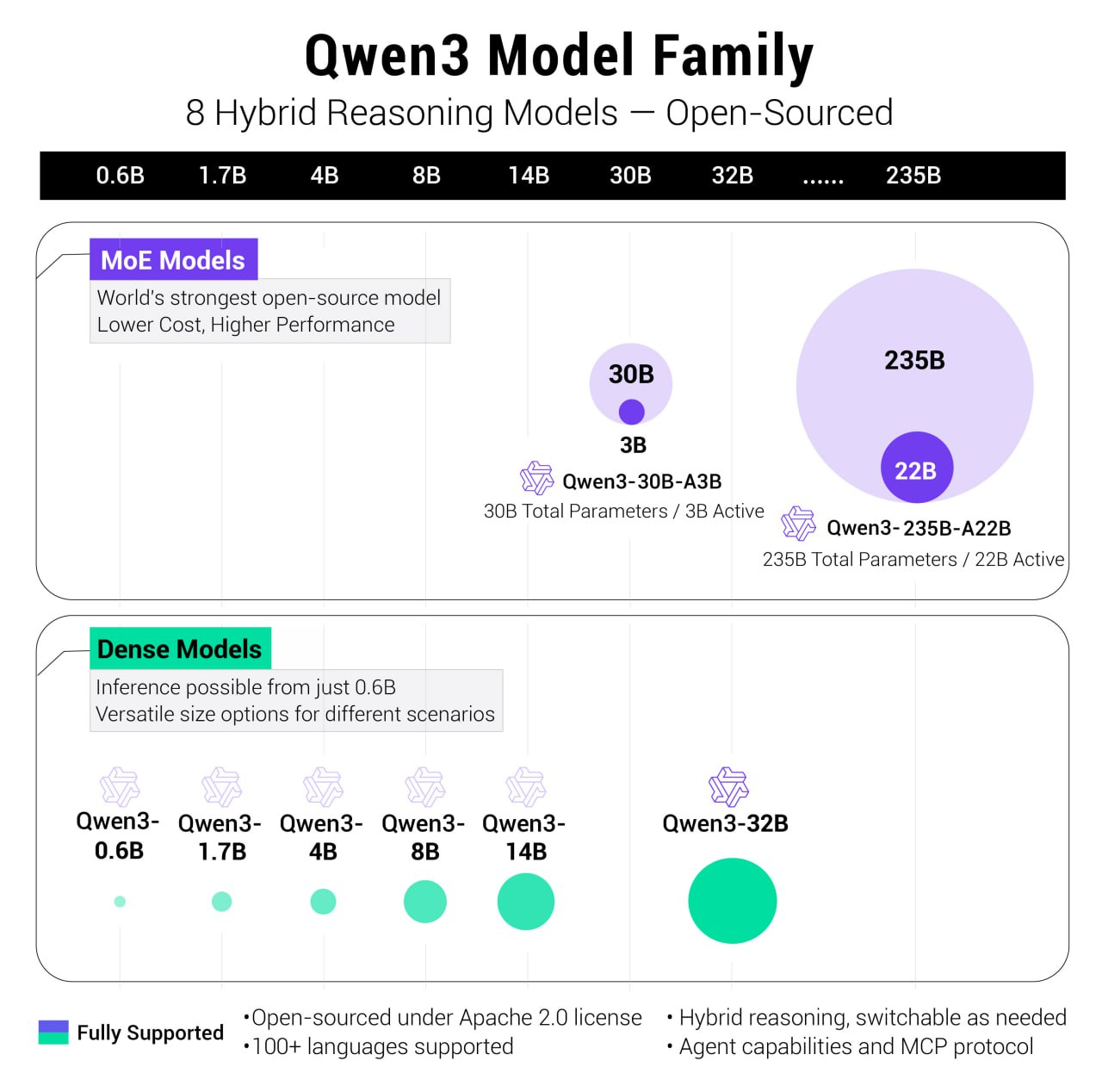
此次,阿里开的源模型有Dense模型,也有MoE模型。其中,开源了两个 MoE 模型的权重:Qwen3-235B-A22B,一个拥有 2350 多亿总参数和 220 多亿激活参数的大模型,以及Qwen3-30B-A3B,一个拥有约 300 亿总参数和 30 亿激活参数的小型 MoE 模型。
六个 Dense 模型也已开源,包括 Qwen3-32B、Qwen3-14B、Qwen3-8B、Qwen3-4B、Qwen3-1.7B 和 Qwen3-0.6B,均在 Apache 2.0 许可下开源。可以直接商用。
Qwen 3系列的其中一个创新点在于其"混合型"模型设计,可以在深度思考这种慢思考模式(用于复杂的逻辑推理、数学和编码)和快思考模式(用于高效、通用的聊天) 之间的无缝切换 ,确保在各种场景下实现最佳性能。
这意味着,用户终于不需要手动操作开启并关闭“深度思考”功能,且担心模型过度思考的问题了,此前,很多大模型用户反馈称,大模型动不动就深度思考输出长篇大论,很多小问题也如此完全没必要。
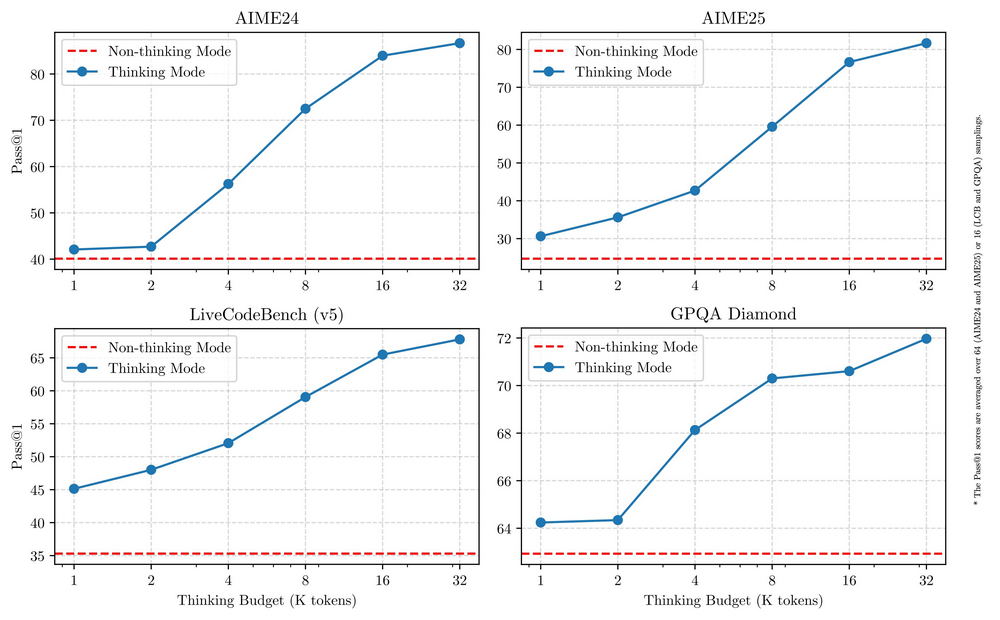
关键在于,这种快慢思考灵活切换的模式能有效的降低成本,阿里在博客中称:这两种模式的结合大大增强了模型实现稳定且高效的“思考预算”控制能力。这样的设计让用户能够更轻松地为不同任务配置特定的预算,在成本效益和推理质量之间实现更优的平衡。
在部署方面,阿里称仅需4张H20即可部署千问3满血版,显存占用仅为性能相近模型的三分之一。这意味着相比相比满血版deepseek R1,部署成本大降75%~65%。
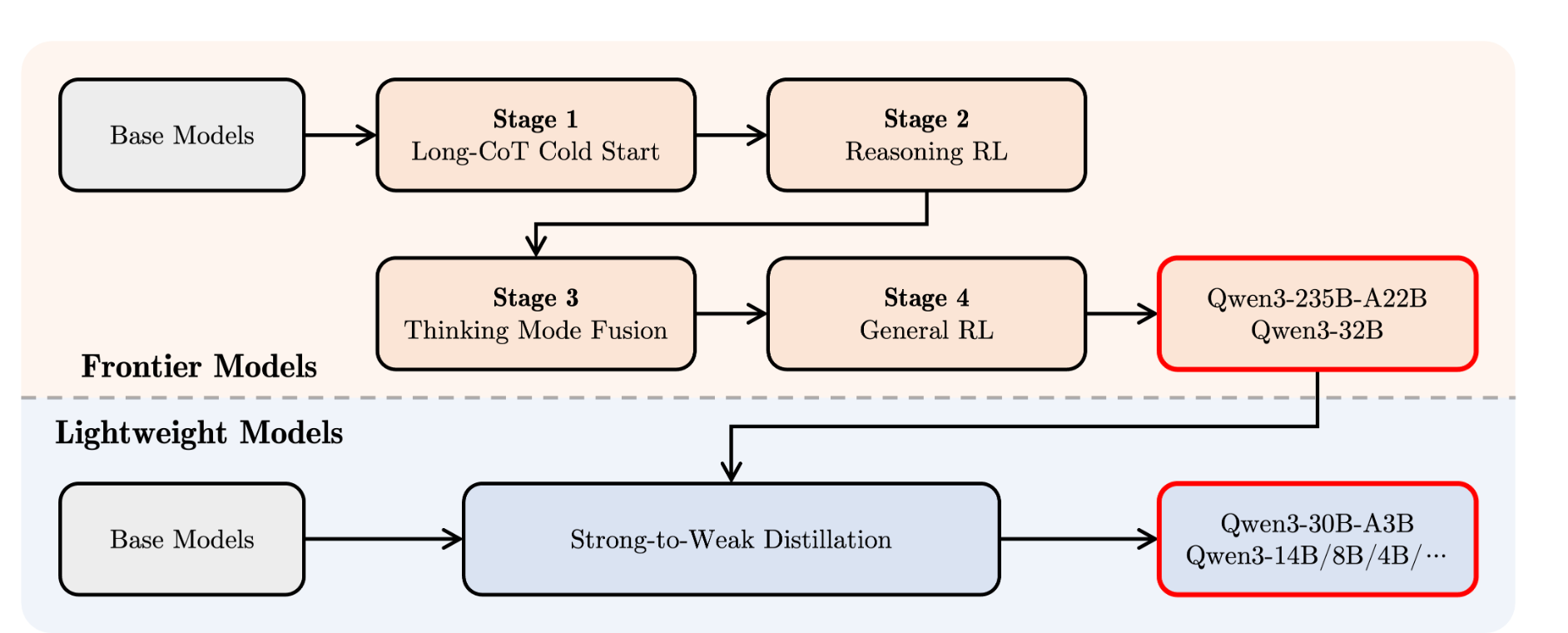
阿里介绍称,Qwen3经过了四阶段的训练流程,相当于,先教基础→再练深度思考→混合快慢模式→最后全面优化。阿里表示,Qwen3在工具调用、指令执行和数据格式处理方面表现优秀。建议搭配Qwen-Agent使用,它能简化工具调用的代码实现。
此次,阿里还专门优化了 Qwen3 模型的 Agent 和 代码能力,同时也加强了对 MCP 的支持。在示例中看到, Qwen3 可以丝滑的调用工具。
开源正在成为阿里核心的AI战略,从2023年起,阿里通义团队就陆续开发了覆盖0.5B、1.5B、3B、7B、14B、32B、72B、110B等参数的200多款「全尺寸」大模型。
在此前的一次采访中,通义相关负责人曾告诉蓝鲸新闻,“开源不是目的而是结果。只有做出真正有竞争力的产品,开源才有意义。这倒逼我们必须做到两点:一是模型性能要达到全球SOTA水平,二是要能媲美甚至超越闭源模型。”


