
摘要:AGI行业将迎来新格局。

AGI行业将迎来新格局。
@科技新知 原创
作者丨林曦 编辑丨赛柯
在人工智能领域,OpenAI的一举一动牵动着全球从业者的心。近日,OpenAI宣布停止对中国的API服务,将对中国“断供”。
北京时间6月25日凌晨,有开发者收到了OpenAI的邮件,邮件写道:“数据显示,您组织的APl流量来自OpenAl目前不支持的地区。”并表示:“从7月9日起,我们将采取额外措施,阻止来自不在我们支持的国家和地区列表中的地区的APl流量。”
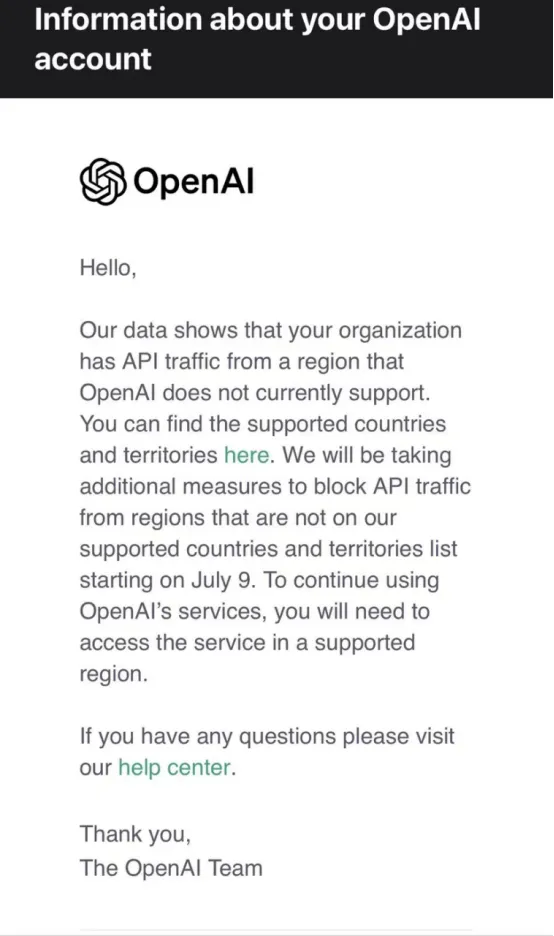
根据OpenAI官网,支持访问API服务的国家和地区总计161个,不包括中国内地与中国香港。OpenAI官网还提到,除了被允许的国家和地区外,“访问或提供访问我们的服务,可能会导致您的账户被封锁或暂停。”
科技新知从多位AI大模型从业者处获知,确实收到了这封邮件。业内人士认为,OpenAI出于对成本以及数据安全的考量而停止在中国的API服务。
2023年3月,OpenAI宣布开放API,允许第三方开发者通过API将ChatGPT集成至他们的应用程序和服务中。The Information报道,自去年12月起, OpenAI年化收入翻了一倍,达到34亿美元,其中32亿美元源自其订阅服务与API访问。
借助OpenAI大模型“套壳”创业的公司,将迎来毁灭式打击。“对于依赖OpenAI API的‘套壳’公司来说,他们可能需要寻找其他的API服务供应商或者寻找替代方案来维持其服务。”中国人工智能学会专家、深度科技研究院院长张孝荣对科技新知表示,“这可能需要对新的供应商进行调查,了解其服务的特点、质量和价格,并进行相应的技术调整和适配。”
Part.1
国内厂商“抢单”

技术社区的讨论很快传导到市场,OpenAI的“停服”消息一出,国内AI大模型公司纷纷上线“迁移计划”,且一举打出“免费”旗号。
6月25日,百度智能云千帆推出大模型普惠计划,为新注册企业用户提供0元调用、0元训练、0元迁移等服务,其中,文心旗舰模型首次免费,针对OpenAI迁移用户额外赠送与OpenAI使用规模对等的ERNIE3.5旗舰模型Tokens包。
阿里云百炼宣布,将通义千问GPT4级主力模型Qwen-plus的API定价为OpenAI的1/50,并为中国开发者提供2200万免费tokens和专属迁移服务。
腾讯云为新注册企业用户免费赠送腾讯混元生文1 亿Tokens,还将为新迁移企业用户提供免费专属迁移工具和服务。
除了头部大厂,国内几个AI大模型代表性初创企业也纷纷争夺这波流量。智谱AI推出了“OpenAI API 用户特别搬家计划”,为开发者提供1.5亿Token,以及从OpenAI到GLM的系列迁移培训;Kimi当天发布迁移方案,称Kimi开放平台接口完全兼容OpenAI,最快5分钟实现搬家;零一万物发起“Yi API 二折平替计划”,推出了平滑迁移至Yi系列大模型的服务。
硅基流动(SiliconFlow)甚至将Qwen2-7B、GLM-4-9B、Yi-1.5-9B等开源大模型永久免费,创始人袁进辉在朋友圈称:“今天SiliconCloud把一大批模型都免费了,大家轻薅,别给整破产了。”
显然,国内大模型公司试图抓住这一关键“窗口期”,为自己争取到更多的开发者用户。
著名财经金融评论员余丰慧对科技新知表示,“大模型公司如百度智能云等推出‘特别搬家计划’,不仅是为了抢占市场份额,也是在展现其技术支持和服务能力,有助于快速建立用户信任。”
实际上,早在618前夕,国内大模型公司就已经展开了价格战。从降价到免费,这波降价潮也体现了国内大模型行业的激烈竞争。
5月,大模型行业开始加码性价比。发布GPT-4o时,OpenAI宣布调用GPT-4o模型API 的价格比GPT-4Turbo下降一半,处理100万Token只用5美元;Google也将其主力模型 Gemini 1.5 Pro的调用价格调低了一半,处理100万Token只要3.5美元。
但国内大模型公司可不是打五折这么简单,而是动辄90%的降价幅度。
5月11日,智谱AI降价80%,入门级产品GLM-3 Turbo模型调用价格从5元/百万Tokens降到1元/百万Tokens;5月15日,字节的豆包大模型对外提供服务,并将处理输入文本的价格定在0.8元/百万Tokens,宣称比行业水平便宜了99.3%;5月21日,阿里Qwen-Long API输入价格降到0.5元/ 百万 Tokens;百度宣布主力模型文心一言ERNIE Speed和Lite模型免费;腾讯宣布轻量大模型 “混元-lite” 免费,最高配置的万亿参数模型 “混元-pro” 降至300元/百万 Tokens,降幅70%。
“通过提供价格优惠和高质量的替代服务,这些公司不仅能够在短期内吸引客户,还有机会在长期内培养用户忠诚度。一旦用户习惯了新的服务,并发现其满足或超越了他们的期望,他们可能会长期留存。”大数据业务分析师、北京社会科学院副研究员王鹏对科技新知表示。
用低价扩大用户规模,再用服务留存用户,这是正确的思路。然而,便宜并不等于好用,在尚未跑通应用场景的情况下,国内大模型公司开始卷价格,AI热潮下的市场焦虑极其严重。
Part.2
AGI行业面临洗牌

OpenAI停服,国内大模型公司反应迅速,意味着市场将极速调整。
API即应用程序编程接口(Application Programming Interface),应用开发者等企业用户可通过接入OpenAI的大模型服务,在各类应用软件中植入ChatGPT机器人的AI能力,将一个普通软件升级为AI应用。
因此,OpenAI停止对中国的API服务,直接冲击了不具备自研大模型能力的大模型开发商。目前,他们可以使用海外服务器,绕开限制接入API;否则,他们就必须选择国内其他的大模型API。
对此,余丰慧指出,依赖OpenAI API的初创企业和研发团队可能会面临服务中断,影响产品开发进度和用户体验。其次,对于使用其技术进行AI创新的研究机构和高校,可能会阻碍相关研究项目的进展。
此外,这可能会促使行业加大对本土AI技术的投资与自主研发,长期看有利于本土生态的构建,但短期内可能遭遇技术替代的挑战。
6月26日,360集团创始人、董事长@周鸿祎在微博发布视频称,他认为“OpenAI对中国地区停止服务,只能加速中国自己大模型产业的发展,未必是坏事”,他解释道,“OpenAI的API无法调用,这逼着国内应用只能选择国产大模型,而国产大模型与GPT的差距已经逐渐缩小了。”
国产自研大模型的能力,仅次于美国,正逐渐展现出竞争力。
根据斯坦福最新公布的大模型测评榜单HELM MMLU,通义千问Qwen2-72B得分为0.824,与GPT-4并列全球第四。
6月25日,每日经济新闻发布了《每日经济新闻大模型评测报告》(第一期),报告显示,国产大模型正在全面赶超海外大模型。
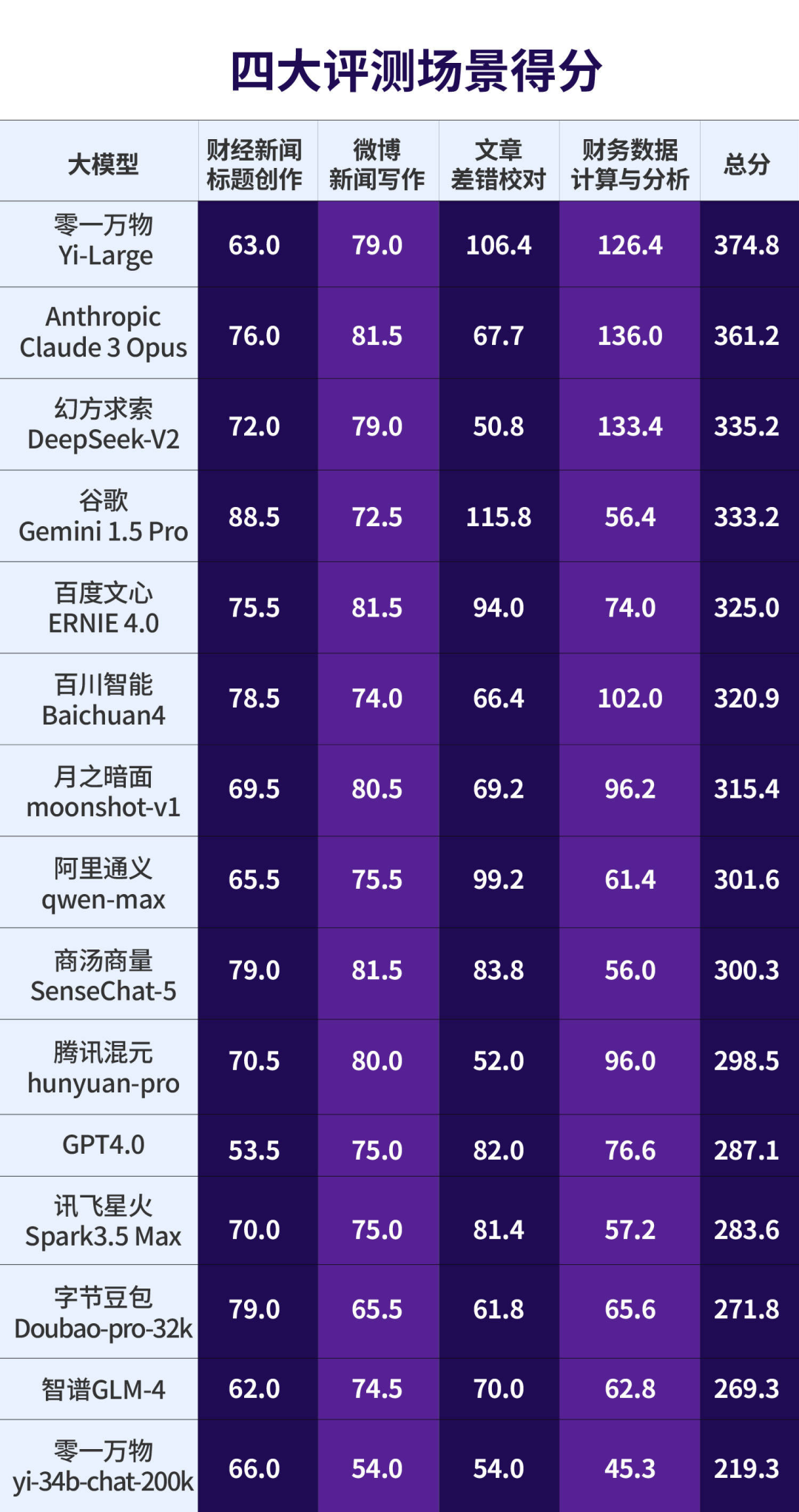
零一万物Yi-Large成为最大“黑马”,在“财经新闻标题创作”“微博新闻写作”“文章差错校对”“财务数据计算与分析”四大应用场景的总分排名第一。幻方求索DeepSeek-V2、百川智能Baichuan4则在“财务数据计算与分析”场景显示出强大的数据计算和分析能力。而一直备受各界推崇的GPT 4.0在本次评测中表现不佳,甚至在“财经新闻标题创作”场景中排名垫底。
事实上,在中文语境中,国内自研大模型展现出了显著的优势,特别是在处理中文自然语言任务方面,这些模型能够更好地理解和生成中文内容,从而在中文问答、对话、翻译等任务中表现出色。
例如,腾讯混元大模型,作为腾讯全链路自研的通用大语言模型,其参数规模超过万亿,展现了卓越的中文理解与创作能力、逻辑推理能力以及可靠的任务执行能力,其AI助手App腾讯元宝即展现了强大的AI能力和丰富的应用场景。
此外,中国的大模型更加注重图像、视频等多模态数据的研究,展现出强大的适应性和泛化能力。
近日,智源研究院院长王仲远在接受网易科技采访时指出,“(AI行业)基础模型依然亟待突破,整个国内的大模型依然处在赶超GPT3.5的阶段。国内大模型在中文的语境下已经开始能够接近逼近GPT4,但是GPT4也在不断研发新版本,所以依然处于追赶的局面。”
Part.3
国产大模型创新路

摈弃GPT,走向全面自研,这对于国产大模型来说,这是一条真正创新的道路。
实际上,去年12月,OpenAI公司就已经暂停字节跳动访问API,而这是因为,字节跳动使用OpenAI的技术来帮助开发自己的人工智能大模型。根据第一财经报道,字节跳动承认,公司2023年初开始探索构建大模型,有部分工程师将GPT的API服务应用于较小模型的实验性项目研究中。
无独有偶,去年11月,零一万物也被传出套壳消息,其回应媒体称,在训练模型过程中,沿用了GPT/LLaMA的基本架构,但需要说明的是,借鉴架构并不能跟“套壳”或者“抄袭”直接划等号。
过去,国产大模型的自研之路,或多或少都借鉴了OpenAI等国外大模型的技术,这是不可否认的事实。
“随着外部竞争的减少,国内AGI(通用人工智能)行业或将进入一个加速整合与创新的阶段。”
余丰慧指出,企业间的竞争将更加聚焦于技术突破、应用场景的拓展以及用户体验的优化。头部企业可能会加大研发投入,推动算法模型的迭代升级,力求在性能上超越国际同类产品。
王鹏也表示,OpenAI的停服,将加速国内AGI行业的技术创新。为了减少对外部技术的依赖,国内企业需要加大研发投入,突破技术壁垒,开发出更高效、更智能的大模型。
目前,随着算法和算力等技术提升,国产大模型正纷纷进入万亿参数时代。现阶段,从算法创新到数据端比拼,国产大模型跟国际水平仍有一定差距。
从技术路线看,国内大模型不具备原创理论支撑,研发以追随海外先进成果为主。例如,人工神经元模型、知识图谱、深度学习框架、Transformer架构等开创性技术,大多由美国科学家提出。
从全球范围来看,中文语料库跟英文数据集的差距不容小觑。受制于搭建数据集较高的成本以及尚未成熟的开源生态,国内开源数据集在数据规模和语料质量上相比海外仍有较大差距,数据来源较为单一,且更新频率较低,模型的训练效果受限。
技术攻坚后,推动场景应用落地,发挥商业化的价值,也是国内AGI行业需要前进的方向。随着OpenAI的退出,外狼”正在减少,国产大模型行业需要走出自己的新道路。

